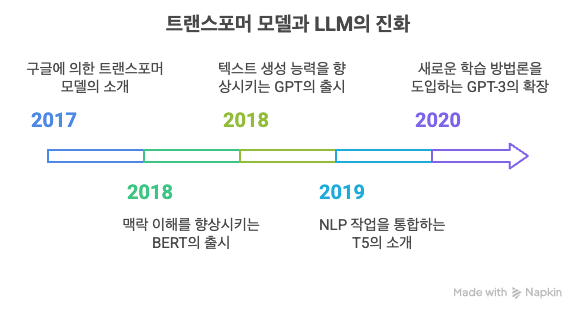
강화 학습과 인간 피드백(Reinforcement Learning from Human Feedback, RLHF)은 인공지능, 특히 대규모 언어 모델(LLM)을 훈련시키는 중요한 방법론입니다. 이 기술은 AI 시스템이 인간의 가치와 선호도에 더 잘 부합하도록 만드는 데 중요한 역할을 합니다. RLHF란 무엇인가?RLHF는 AI 모델이 인간의 피드백을 바탕으로 자신의 출력을 개선하는 학습 프로세스입니다. 기본적으로 AI 시스템이 생성한 여러 응답 중에서 인간 평가자가 더 나은 응답을 선택하고, 이 선호도 데이터를 활용해 모델을 미세 조정하는 방식입니다. RLHF의 작동 원리RLHF는 일반적으로 다음 세 단계로 구성됩니다:기본 모델 훈련: 먼저 대규모 텍스트 데이터로 언어 모델을 사전 훈련합니다.보상 모델 ..